La Wayback Machine, o Archive.org, è la più importante libreria digitale del mondo: non è semplicemente un archivio internet con oltre 330 miliardi di pagine web; è la memoria storica di internet, l’unico strumento con cui potresti dare un’occhiata a com’era un sito web in qualunque momento della sua esistenza, dal 1996 a oggi. Sembra che il nome Wayback Machine sia stato ispirato dalle Avventure di Rocky e Bullwinkle and Friends, un cartone animato all’interno del quale la macchina Wayback ricopriva un ruolo di primo piano. Per quanto riguarda il funzionamento del sito web Archive.org, è presto detto: dei crawler scansionano periodicamente il più alto numero di pagine web possibili e ne catturano un’istantanea, che viene memorizzata all’interno dell’archivio internet su una sorta di linea temporale.
Come può essere utilizzata la Wayback Machine?
La Wayback Machine può essere utilizzata per ottenere il maggior numero di informazioni possibili su un determinato sito web, non solo per motivi ludici. Se da un lato l’archivio internet per eccellenza permette di dare un’occhiata a un sito web in un momento qualsiasi della sua storia per pura curiosità (consente, ad esempio, di vedere com’era Google agli esordi), dall’altro può essere utilizzato per almeno 4 motivi:
- per valutare la storicità e il passato di un determinato dominio prima di affondare il colpo in un’asta (ad esempio per accertarsi che non sia stato bannato in passato)
- per recuperare gli url e i contenuti eliminati o persi nel tempo
- per vedere com’era un sito prima di una migrazione o prima che perdesse traffico e posizionamenti (e capire come, e soprattutto dove, intervenire)
- per confrontare il file robots.txt e la sitemap nel tempo.
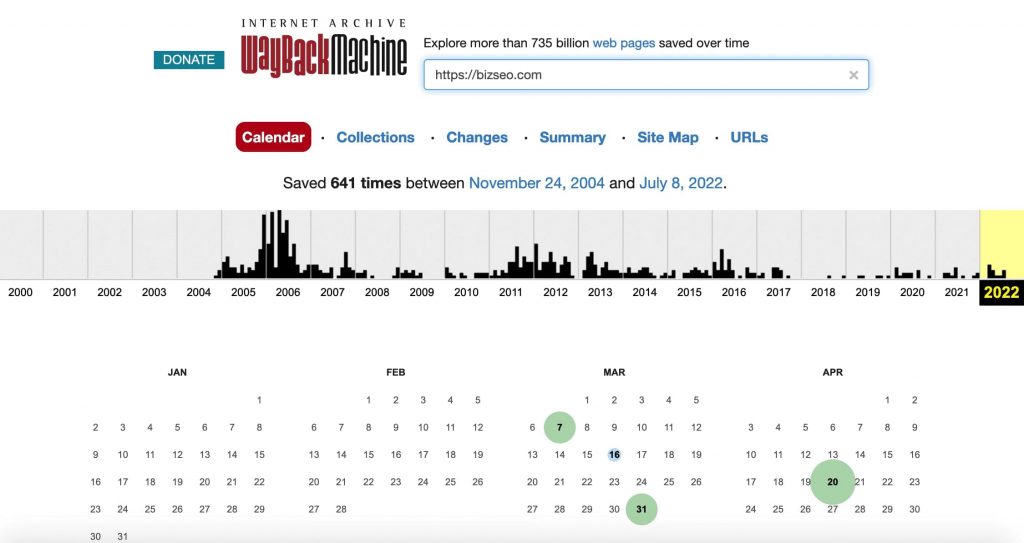
L’utilizzo di Archive.org è piuttosto intuitivo: all’interno della barra di ricerca inseriamo il sito che vogliamo analizzare; le date evidenziate da un cerchio indicano i giorni in cui i crawler della Wayback Machine hanno effettuato una scansione del sito; cliccando su di esse, possiamo consultare le pagine di quel sito così com’erano nel momento in cui il bot ha scattato le istantanee.
Nel prossimo paragrafo vedremo come utilizzare la Web Archive.org per recuperare gli url e la struttura di un sito prima che venisse effettuata una migrazione, un’ottima soluzione soprattutto se non è possibile consultare una Sitemap o una scansione di Screaming Frog del sito precedente.
Come recuperare un sito web con la Wayback Machine
Questo paragrafo ci mostra perché Archive.org non è un semplice archivio internet. Come abbiamo anticipato poche righe più su, immaginiamo di trovarci in una situazione scomoda: abbiamo lanciato la nuova versione del sito senza ricordarci di mappare gli url della versione precedente e ora, per vari motivi, abbiamo bisogno di recuperare una struttura che consideravamo superata. O, in alternativa, abbiamo appena recuperato un sito scaduto e vorremmo riproporre la stessa struttura del sito precedente. Cosa possiamo fare in questo caso? La soluzione che stiamo per vedere insieme è stata proposta in lingua inglese da exposureninja.com, in un articolo dal titolo How To Extract Your Website’s URLs from Archive.org.
I passaggi da compiere sono 5:
- Copiamo sul browser, nella barra dell’url, la stringa https://web.archive.org/cdx/search/cdx?url=example.com*&output=txt&from=date&to=date, ricordandoci di sostituire example.com con il dominio di nostro interesse e i due frammenti “date” con gli estremi dell’intervallo che ci interessano. Se, ad esempio, vogliamo consultare l’elenco degli url di bizseo.com dal 2012 al 2016, incolliamo sul browser la stringa https://web.archive.org/cdx/search/cdx?url=bizseo.com*&output=txt&from=2012&to=2016 e otterremo questo risultato:
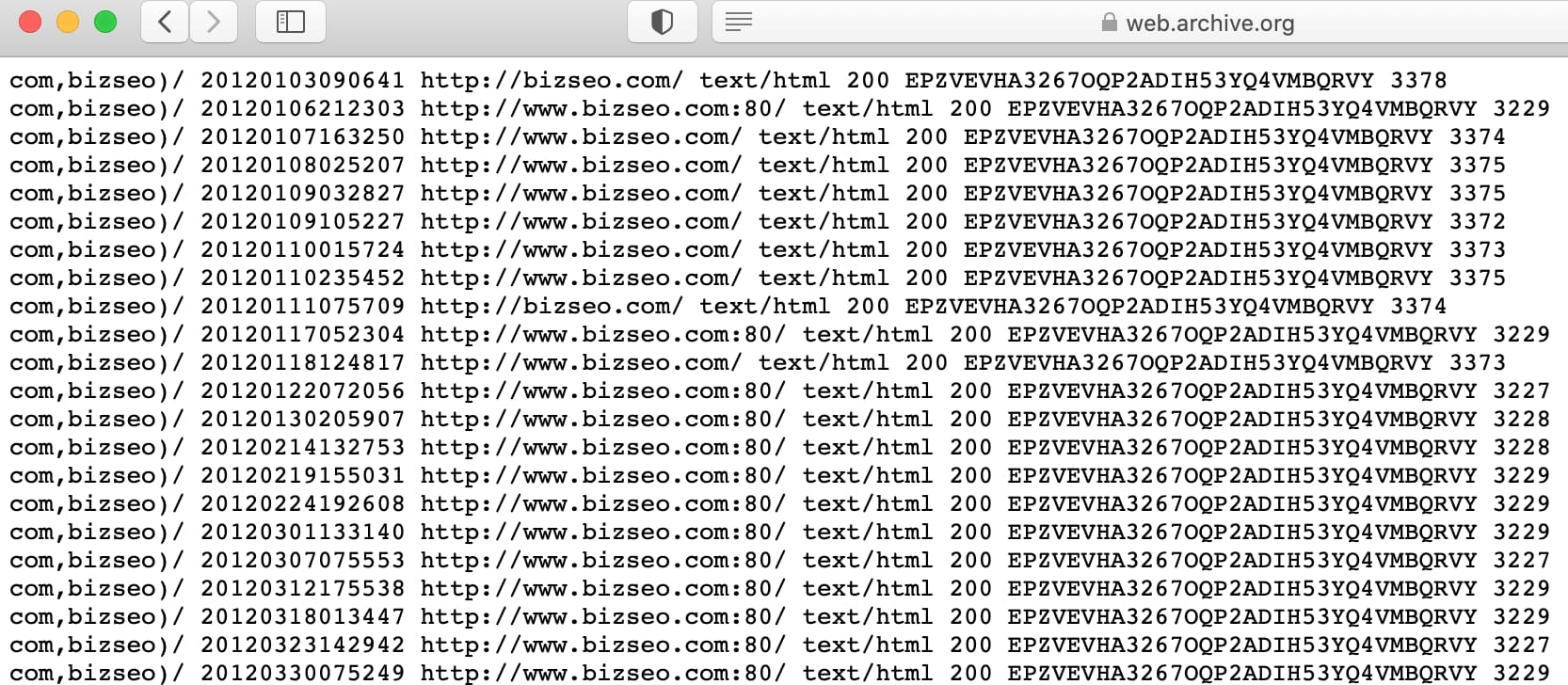
- Con un semplice copia-incolla portiamo la lista intera su un file Excel e, attraverso l’opzione “Testo in colonne” (la trovi sotto “Dati”), dividiamo i dati in colonne utilizzando lo spazio come delimitatore.
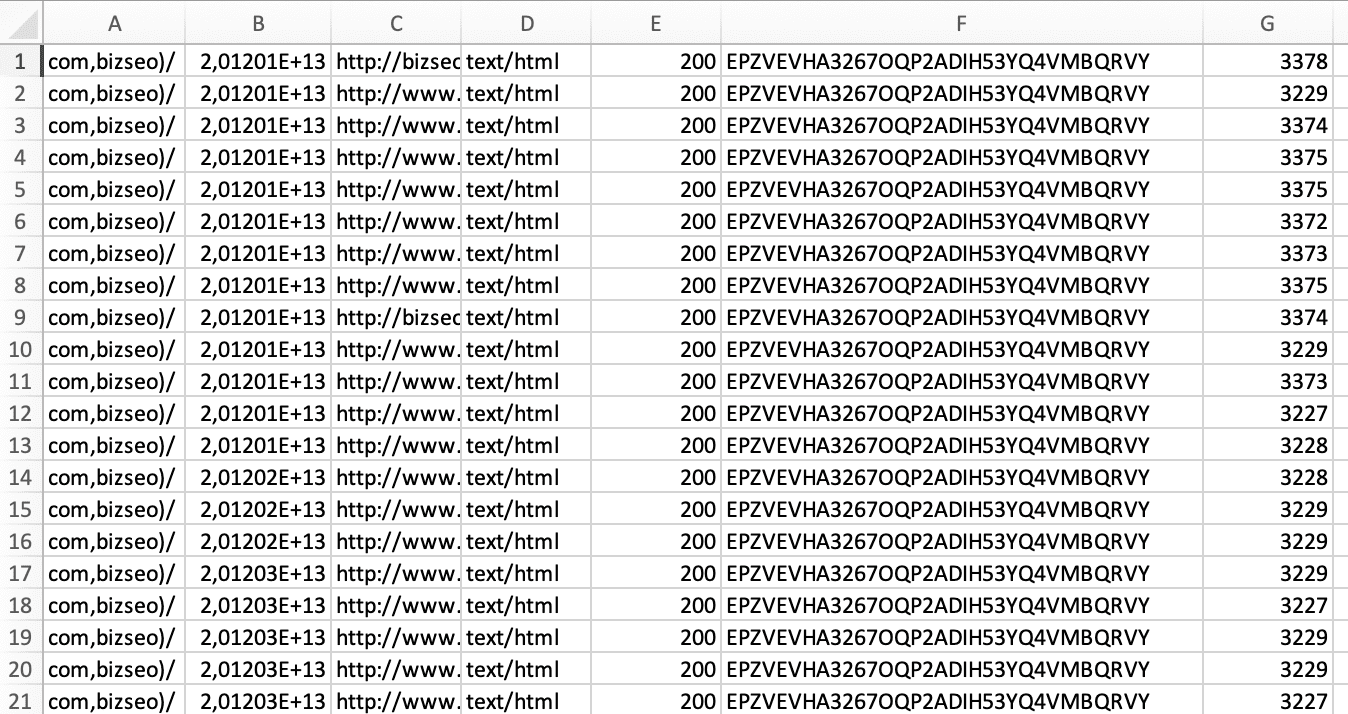
- Rimuoviamo tutte le colonne, tranne quella degli url
- Attraverso la funzione “trova – sostituisci”, rimuoviamo tutti i “:80 dagli url”
- Attraverso la funzione “rimuovi duplicati”, eliminiamo gli url duplicati
Il risultato è in un file Excel che contiene tutti gli url del sito in questione per il periodo selezionato. Una sorta di sitemap pronta per essere lavorata e confrontata con la nuova versione del sito.